Imagine this: your team is gearing up for a high-stakes business review, only to discover that your dashboards are riddled with missing values and inconsistent fields. Frustrating, right? Unfortunately, scenarios like this are all too common when data pipelines behave unpredictably. Data flows can break without warning, leaving teams scrambling to fix issues that could have been prevented. This is where Data Contracts change the game. Instead of leaving teams to react to broken pipelines, they create clear agreements about what data should look like, when it should arrive, and how it should behave.
For data professionals looking to upskill and stay ahead in a data-driven world, understanding Data Contracts isn’t just helpful—it’s a strategic advantage. In this article, we’ll explore what Data Contracts are, why they matter, and how you can implement them to strengthen your pipelines and future-proof your career.
The Problem: Unreliable Data Pipelines
Data pipelines are the backbone of modern organizations. They move information from sources like customer platforms, IoT devices, or internal databases to destinations such as analytics dashboards, reporting tools, or machine learning models. Yet, these pipelines are surprisingly fragile.
When one team makes a schema change without notifying downstream users, entire systems can break. Inconsistent data formats, missing fields, or unexpected null values create headaches for engineers and analysts alike. Instead of focusing on generating insights, teams spend countless hours firefighting issues.
Consider a sales analytics system that suddenly loses the “region” field. Dashboards fail, executives see incomplete numbers, and teams scramble to identify and fix the problem. These incidents highlight a key issue: data flows often lack clear, standardized expectations. Without a mechanism to set rules and define expectations, pipelines become prone to errors, and decision-making suffers. This is precisely why Data Contracts are gaining attention—they provide a structured approach to prevent these disruptions before they happen.
What Are Data Contracts?
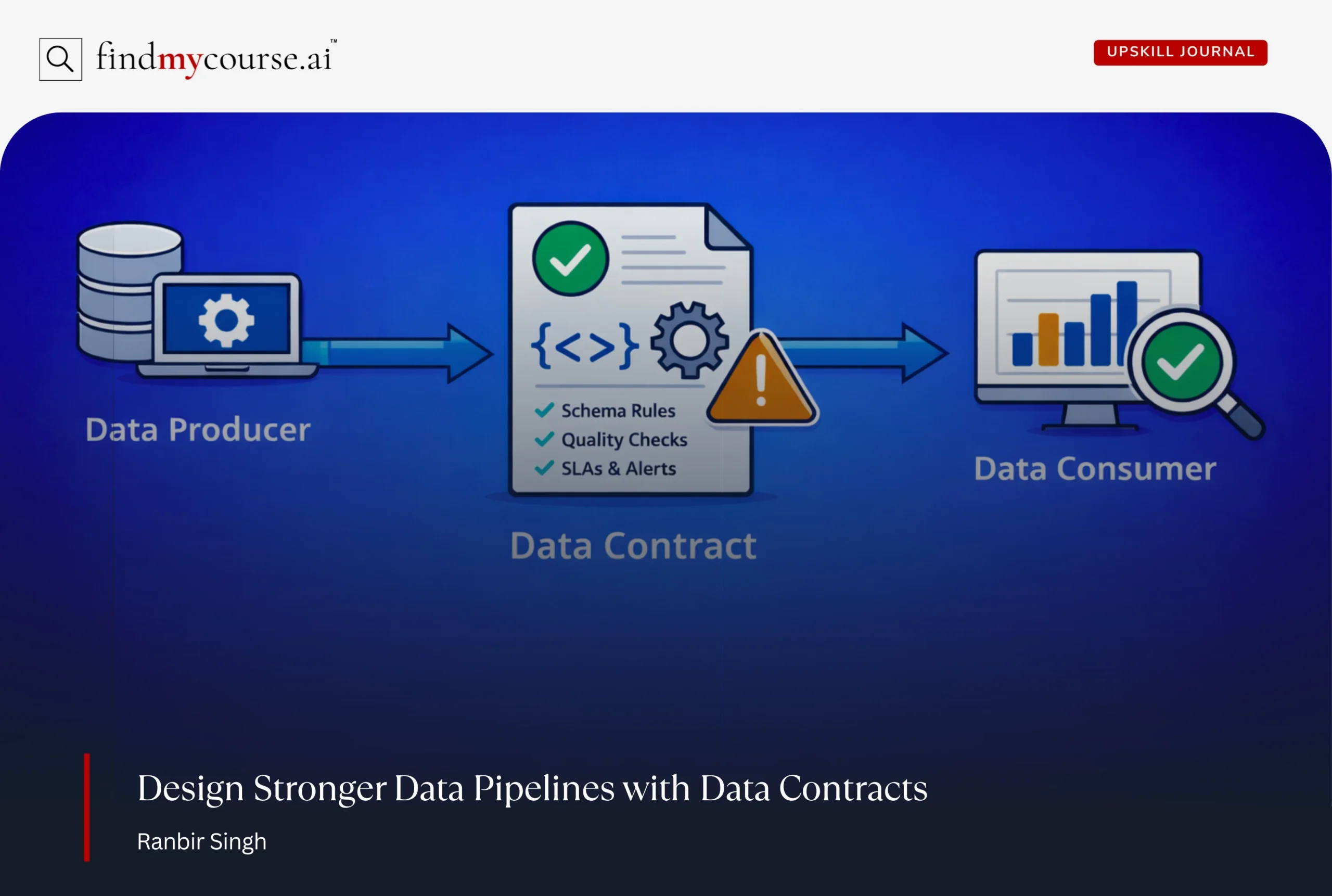
At their core, Data Contracts are formal agreements between data producers and data consumers. They spell out what data should look like, the rules it must follow, and how it should behave. In simpler terms, a Data Contract is like saying, “If you send us this data, it must meet these expectations.”
These agreements cover three main areas:
- Schema definitions: What fields should exist, what types they should have, and any constraints (like integer vs string).
- Data quality expectations: Rules around null values, accepted ranges, or valid formats.
- Delivery requirements: How often the data should arrive, acceptable latency, and service-level guarantees.
For example, a customer data pipeline might require “customer_id” as an integer, “signup_date” as a valid date, and “email_address” that can’t be null. The contract ensures that these expectations are clear and enforceable.
Moreover, Data Contracts are not just about technical compliance—they also foster trust and collaboration. Teams know exactly what to expect and can focus on using the data rather than guessing if it’s reliable. In a distributed organization, this clarity is priceless.
How Data Contracts Work in Practice
Implementing Data Contracts doesn’t mean starting from scratch. It’s really about introducing structure and automating checks to make sure your pipelines stay consistent, reliable, and predictable. Here’s a step-by-step approach:
Step 1: Define the Contract
The first step is collaboration. Data producers and consumers sit together to agree on exactly what the data should look like. This includes:
- Which fields are required
- The types of each field (e.g., integer, string, date)
- Any constraints (like no null values or specific ranges)
- Delivery expectations (frequency, timing, and service-level guarantees)
Modern data platforms and orchestration tools make it easy to define these rules, whether through code, configuration, or integrated schema management. Here are some examples:
| Tool Type | Examples | Purpose |
| Schema Registry | Confluent Schema Registry, AWS Glue Schema Registry | Stores and manages data schemas so producers and consumers follow the same structure. |
| Data Modeling Tools | dbt | Helps define, transform, and standardize datasets before they move through pipelines. |
| Documentation Platforms | DataHub | Provide a central place to document datasets, schemas, and data ownership for teams. |
The goal is to remove ambiguity and ensure both teams know what to expect.
Step 2: Enforce the Contract
After the defining of contract, automation takes over. As data flows through pipelines, it’s validated against the contract. If the incoming data doesn’t match the agreed-upon schema or fails quality checks:
- Alerts are triggered to notify the right teams
- Data loads can be paused to prevent downstream errors
This step catches issues early, preventing hours of firefighting and avoiding broken dashboards. Modern orchestration and data management platforms such as Apache Airflow often integrate contract enforcement natively, which means your team spends less time chasing errors and more time delivering actionable insights.
Step 3: Monitor and Alert
Data Contracts are not “set it and forget it.” Continuous monitoring is key. Modern tools like Monte Carlo track violations and notify teams immediately when something goes wrong. For example, if data quality drops below an agreed threshold:
- Automated alerts can trigger workflows to fix the issue
- Tickets creation is automatic for rapid resolution
This proactive monitoring prevents small problems from snowballing into major pipeline failures.
By defining, enforcing, and continuously monitoring Data Contracts, organizations turn abstract agreements into operational safeguards that keep their data pipelines running smoothly 24/7.
Best Practices for Implementing Data Contracts
Implementing Data Contracts becomes much easier when teams follow a few practical principles. The table below highlights key practices, what they involve, and how they strengthen your data pipelines.
| Best Practice | What It Involves | Impact on Your Data Pipelines |
| Start With High-Impact Datasets | Focus first on critical pipelines such as executive dashboards, core reporting systems, or machine learning data sources. Starting small helps teams test and refine their approach. | Builds quick confidence in Data Contracts and shows measurable value before scaling across the organization. |
| Include All Stakeholders | Bring data producers, consumers, engineers, analysts, and business teams together to define expectations collaboratively. | Reduces misunderstandings and ensures the contract reflects how the data is actually used. |
| Automate Enforcement | Use tools that automatically validate schemas, data quality rules, and delivery expectations as data moves through pipelines. | Prevents human error, maintains consistency, and allows teams to focus on insights instead of troubleshooting. |
| Version Your Contracts | Track updates to schemas and rules through version control, communicate changes clearly, and test compatibility before release. | Allows pipelines to evolve safely without breaking downstream systems. |
| Foster a Culture of Data Ownership | Encourage teams to take responsibility for the data they create and use, with clearly defined roles and expectations. | Strengthens reliability across the data ecosystem and reduces recurring pipeline issues. |
Getting Started with Data Contracts
If you’re beginning with Data Contracts, start by understanding how structured agreements improve data reliability. Focus on practical learning and gradually apply the concepts to real pipelines.
- Understand schema management: Learn how schemas define structure, data types, and required fields so teams share the same expectations.
- Explore practical learning resources: Courses like Kafka for Developers: Data Contracts Using Schema Registry on Coursera show how contracts work in real streaming systems.
- Practice with a small dataset: Begin by documenting rules for one important dataset such as customer or transaction data.
- Introduce validation gradually: Add checks that alert teams when data breaks the agreed rules.
Conclusion
Reliable data is essential for confident decisions, yet pipelines often break when expectations are unclear. Clear agreements around structure, quality, and delivery help teams catch issues before they reach dashboards or models. As a result, teams spend less time fixing problems and more time generating insights. Over time, this approach builds stronger collaboration and trust in data across the organization.
As data ecosystems continue to grow in scale and complexity, adopting structured practices like Data Contracts helps keep pipelines reliable and future-ready. If you still have questions or want help to start with Data Contracts, feel free to ask our AI assistant anytime.